Пиша това в отговор на Борислав във връзка със статията ми „Въпроси и отговори„:
Да си представим, че Уеб 3.0 е проект, който ти ръководиш – решението на концептуално стратегическо ниво зависи от тебе.Какви идеи, цели и очаквания би заложил в този проект?
Първо трябва да отбележa, че не харесвам терминът Web 3.0. Продължение е на некоректно поставеното определение „Web 2.0“ за развитието на Ajax технологиите, социалните мрежи и блоговете. В момента това определение се използва за две (потенциално) революционни технологии, които ще променят начина, по който общуваме.
Едната позволява потребителите да изграждат физически безжични мрежи с помощта на съществуващата инфраструктура – телефони, pda, лаптопи, лични рутери и т.н. Така практически ще се избегне нуждата от ISP – интернет доставчици. По подобие на P2P мрежите, тези физически мрежи ще са толкова мощни, колко повече потребители има на едно място. Проблемите в момента включват съвместимост на устройствата, слабите батерии, сигурността и не на последно място – силният отпор на производителите на устройства и телекомите.
 Вторият раздел технологии са семантичните. Казвам раздел, защото тук участват много разработки, които заедно позволяват изграждането на инфраструктура в мрежата за мета данни. Тук говорим за софтуерна инфраструктура.
Вторият раздел технологии са семантичните. Казвам раздел, защото тук участват много разработки, които заедно позволяват изграждането на инфраструктура в мрежата за мета данни. Тук говорим за софтуерна инфраструктура.
Малко разяснения: В момента в мрежата има много информация. Може да открием всичко за всички. Google се стравят относително добре със задачата. Всеки, който е прекарал повече време в търсене обаче, е открил, че машините са твърде тъпи. Информацията, която ние генерираме в сайтовете, блоговете, форумите, книгите, снимките и филмите в мрежата е:
В света на компютрите, всичко трябва да е подредено, описано и готово да бъде сдъвкано от алгоритъм. Проблемът днес е, че има просто твърде много информация, която самите ние не можем да осмислим. Все по-трудно става да се намери отговор на въпроса „Къде има добра храна в региона?“ или „Кой е написал книга през 1930г.?“. Ние осъзнаваме какво трябва да се търси, но информация, която трябва да прегледаме е толкова много и е толкова пръсната, че бързо се отказваме.
Отговорът е ново поколение търсачки и интернет услуги. Целта е самите компютри да могат да „осмислят“ данните и да ги сравнят с това, което искаме. За целта трябва да ги научим на концепциите, логиката и езика ни. За целта ни помагат съответно технологии като онтологии, Prolog/Flogic и разпознаване на естествен език (natural language processing).
Има много езици и подходи към онтологиите. Аз работя с OWL. В нашият университет ни преподаваха MIX – модел разработен от TU Darmstadt. Днес пък намерих една лекция от Софийския университет, в която се говори за SHOE. (Впрочем този, който е направил лекцията трябва да бъде разстрелян, за да не се споминат студентите от скука.) Въобще има много подходи, но всички целят едно – създаване на език, който да надгражда сегашните ни методи за представяне на информацията. Този компютърен език трябва да може да опише технически абстрактните концепции от нашият свят и чрез тях да опише всякакви данни. Така, когато имаме две различни таблици, компютърът ще може да си направи извод кои данни какво представляват и да може да ги сравни. Типичен пример е ако в един сайт цените на билетите са в евро с данъци, а в друг – в левове и без данъци.
Тук идва логиката. Компютрите трябва да могат да си вадят изводи на базата на някакви знания и даден контекст. Вече има достатъчно мощни езици, които да се справят със задачата. В един проект се занимавахме малко с Prolog и бях шашнат докъде са стигнали нещата. Това, което липсва към момента са акумулираните знания.
Тези две технологии позволяват на компютрите да си говорят. Така те ще могат да обръщат информация от един контекст в друг и да си вадят изводи на базата на някакви правила. За да могат да се разбират с нас обаче, трябва да могат да разбират езика ни. Той, както знаем, е много сложен и днес търсачките се затрудняват с елементарни изречения. Затова все повече проекти в мрежата са се насочили точно към тази цел. Два типични примера за това са True Knowledge и Powerset.
С помощта на тези технологии, семантичните услуги и търсачки, ще може да бъде изградена семантична мрежа (semantic web), в която цялата информация е индексирана и съпътствана от мета данни. Това ще позволи наистина бърз и точен достъп до неограничени данни – химера за сегашната мрежа.
Сега има два подхода към семантичните мрежи – отдолу нагоре и от горе на долу. Първият е точно описването на информацията с мета данни. Вторият е създаването на услуги, които да разпознават езика ни и да осмислят обърканите масиви с информация. Кой подход аз бих приложил зависи от това какво приложение създавам и за кой.
Първият подход е подходящ за корпоративен софутер и интеграция на системи. Когато нужните данни и цели бъдат достатъчно добре и абстрактно описани, вече превеждането на информация от един формат в друг е въпрос на няколко функции. В много случаи този „превод“ ще може да бъде осъществен визуално и дори автоматично. Разбира се, ще искам функционалността на всички системи да бъде изведена под формата на интернет услуги (web services), което ще позволи още по-лесна интеграция.
Това, което липсва в момента в тази сфера са стандартите и инструментите. Липсва единен език за онтологии и за семантично описване на интернет услуги, инструменти за създаване, интегриране и версионализиране на услуги и онтологии. Има няколко течащи проекти в тази насока. Във фирмата, в която работя – Software AG, участваме в няколко от тях – Neon, SemanticGov и Nessi. Трите проекта са с европейско финансиране, партньори са както компании, така и обществени институции, а целите – решаването на горепосочените проблеми. Мисля, че нещата вървят доста добре.
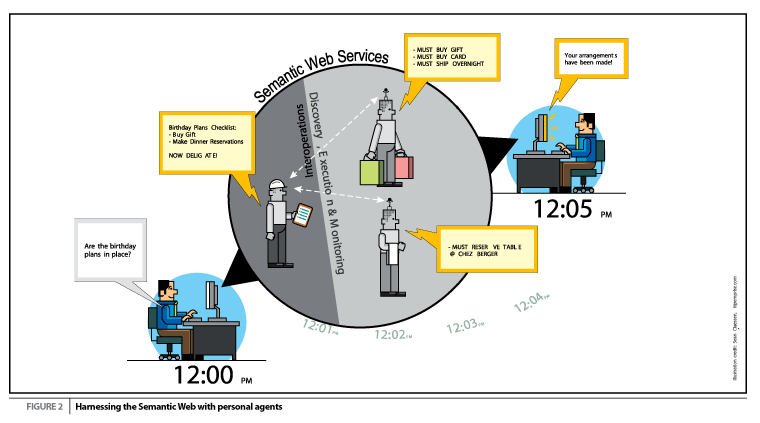 От гледна точка на потребителя, интеграцията на системите на различни фирми и институции трябва да остане прозрачна. За него трябва да съществува само удобен графичен интерфейс, който му дава всичко. С помощта на технологиите, които описах горе това е възможно, но разработването им ще отнеме много време. Тук идва мястото на втория подход. При него се използват технологии за разпознаване на естествен език за да се извлече абстрактна информация от свободния текст, в който са повечето данни в мрежата. Това също помага да се разбере по-точно въпроса на потребителя – какво точно търси. Тези технологии също са още в разработка, но когато са готови, ще са полезни веднага за цялата мрежа. Това е защото сами ще извличат мета данните от интернет страниците, т.е. нямат нужда от нещо повече от сегашната инфраструктура. Те ще променят коренно интерфейсите и начина по който искаме информация от машините.
От гледна точка на потребителя, интеграцията на системите на различни фирми и институции трябва да остане прозрачна. За него трябва да съществува само удобен графичен интерфейс, който му дава всичко. С помощта на технологиите, които описах горе това е възможно, но разработването им ще отнеме много време. Тук идва мястото на втория подход. При него се използват технологии за разпознаване на естествен език за да се извлече абстрактна информация от свободния текст, в който са повечето данни в мрежата. Това също помага да се разбере по-точно въпроса на потребителя – какво точно търси. Тези технологии също са още в разработка, но когато са готови, ще са полезни веднага за цялата мрежа. Това е защото сами ще извличат мета данните от интернет страниците, т.е. нямат нужда от нещо повече от сегашната инфраструктура. Те ще променят коренно интерфейсите и начина по който искаме информация от машините.
Аз бих работил по първият подход – от долу нагоре. Вярвам, че трябва бързо да се стигне до единни стандарти преди да имаме няколко силни продукта, които да са „почти“ съвместими и се борят за надмощие. Това се е случвало вече няколко пъти в индустрията и не е добре за клиентите. Втората причина е, че при този подход се получават по-бързо резултати за бизнеса. Той е тази, който има нужда от бърза и лесна интеграция. Вече получените мощни интернет услуги могат да се предложат на потребителите под формата на най-прост формуляр в интернет страница.
Това, върху което също бих работил, е графични инструменти за интеграция на системи и интернет услуги. Първото е сложно, защото потребителят трябва да разбира много добре от фирмените системи, който използва. Второто е по-просто когато услугите са добре описани. Големите играчи в SOA от няколко години се мъчат да извадят добри продукти в тази насока. В проектът, по който работих в края на миналата година, използвахме точно такива продукти. За сега обаче не ми е известно да има добър цялостен пакет на пазара.
Друг проблем също е, че всички се целят в големите корпорации с мощни продукти с много възможности и високи цени и изисквания. Това е нормално, защото има много такива клиенти и всички искат да конкурентоспособни, а SOA е следващото велико нещо. Както винаги обаче, се забравя дългата опашка – малките фирми, които предлагат услуги. Някой от тях вече са влезли в мрежата – имат си собствени сайтове или са част от портали като Ebay или Amazon. За да могат да се метнат на SOA влакът обаче, трябва или на похарчат луди пари, или да наемат някой като мен да им създаде интернет услуги и онтологии и да ги поддържа след това. Има open-source проекти, които могат да използват, но те са твърде академични и няма да могат да се справят. Липсват точно лесни инструменти, насочени към този пазар. В интерес на истината не е трудно да се направят, стига човек да знае какви са технологиите, потенциалните му клиенти и техните клиенти. Тази информация обаче трудно се събира, защото самите фирми не знаят.
До тук общо взето описах всичко, което може да се направи по Web 3.0. В такива проекти обикновено участват няколко големи корпорации и правителствени институции. Всички те работят заедно и стигат до компромиси какво ще се използва. В крайна сметка се стига до там, че всеки дърпа чергата към себе си. Това е, защото всеки е инвестирал в някакви разработки и иска неговото да се наложи, за да не инвестира още в поддържане на чужди стандарти. Така се стига до безкрайните политически игри и надлъгвания. Аз не бих бил част от тях. Харесвам разработките (research) заради академичното търсене на нови технологии, по-абстрактната дефиниция на „краен срок“ и приятния начин на работа, но не и ако трябва да се занимавам с патенти и стандартизация. Реално винаги се стига до там. А и за да повлияеш на тези процеси, трябва да си високо в някоя от водещите софтуерни корпорации.
Затова бих предпочел да се занимавам точно с дългата опашка. Още повече, че в България има много малки фирми, като повечето от тях дори не знаят, че интернет има такъв потенциал и че може да е достъпен за тях.
Надявам се, че съм отговорил на въпроса ти. Малко се разпрострях в обяснения кое какво е и какви са тенденциите, но темата е обширна. 🙂 Питайте ако съм пропуснал нещо.
[tags]онтологии, семантични мрежи, web 3.0, интернет услуги, естествен език, ontology, web service, Software AG, neon, semanticgov, nessi[/tags]
Благодаря ти за изключително интересния и полезен отговор! Това си е цяла статия – много информативна, аналитична и увлекателна. Радвам се, че въпросът ми насърчи създаването на този ценен за всички твои читатели текст.
Много полезно! Става ясно и за тези дето не са много навътре с нещата. След тази статия обаче ще са по-наясно с много неща.
Отдавна се канех да напиша такава статия и въпросът на Борислав беше добър повод. Опитах се да я направя максимално разбираема за хора, които не разбират от материята или дори от информатика. Надявам се да съм успял.
Има ли вече повече яснота по OWL? До къде са стигнали Пролог? Този език възкръсна. Защо не направиш цяла поредица от кратки статии за Онтологиите, за RDF? С какво ще бъдат полезни и каква реализация се очаква в близките месеци. От къде да намерим повече инфо за онтологиите?
ха, наистина много увлекателна статия се е получила…
съвсем случайно попаднах на вашия блог, статията за германия… и после тук! чак сега се наканих да напиша два реда.
Евала! трябват повече хора като вас на малка страна като нашата. Дано да имате късмета и силите да сбъднете всичките си проекти :)))
специално тази статия ми направи много голямо впечатление, защото съм студент по право и в момента изучавам дисциплина наречена „правна информатика“ (което си е нещо като наука за правната информация и нейното практическо приложение, регистри…). Професорът постоянно говори за уеб 3.0, семантични мрежи etc. Сега си мисля, че ми стана една идея по-ясно за какво иде реч 🙂
Поздрави
Направо си страхотен! Четох с отворена уста, чак… Сега ме амбицира да прочета всичко тук.
🙂 Благодаря. Събрал съм всички подобни статии в отделен блог, който се опитвам да покарам от известно време:
Определено това е един от интересните блогове, които съм срещал наскоро из БГ и-нет пространството.Поздравления!