Представете си, че може да прочете няколко милиона книги на няколко езика от последните няколко стотин години. Какво бихте научили от тях? Проблемът е, че това е невъзможно – нито ще ни стигне времето, нито ще можем да съберем и осмислим цялата тази информация. Преди години няколко асистента в Харвард заедно с Google са решили да направят нещо по този въпрос. Използвали са огромната база данни от милиони сканирани книги на Google и са пуснали данни за честотата на използвани фрази. Фразите могат да бъдат от една или повече думи и за всяка се пресмята през коя година колко пъти е била споменавана в изданията на различни езици. Така получаваме таблица с няколко милиарда реда. След това са направили инструмент, с който всеки може да анализира данните. Повече за N-gram проекта може да видите в тази и в тази TED лекции.
В инструмента можем да избираме езици, периоди, термини, както и да сравняваме няколко такива. Графиката ще покаже и процентното отношение на книгите, които споменават зададените фрази спрямо всички издадени през дадената година. Точните проценти обаче не са важни, а сравнението между годините. Реших да изкарам седем графики, за да илюстрирам интересни факти от историята ни. За жалост нямат данни на български, но за нас английската и руската литература би била също интересна.
 Натисни за по-голям размер
Натисни за по-голям размер
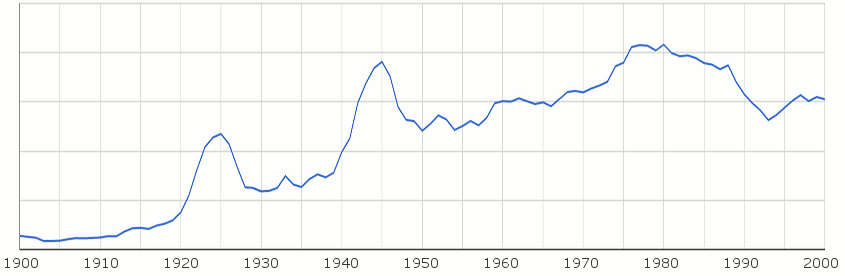
Горната графика показва споменаването на „Болгария“ в руската литература. Ако погледнете данните на Google, ще видите, че преди 1810 практически не се говори, има засилване около 1925, малък скок около освобождението и доста големи около световните войни.
 Натисни за по-голям размер
Натисни за по-голям размер
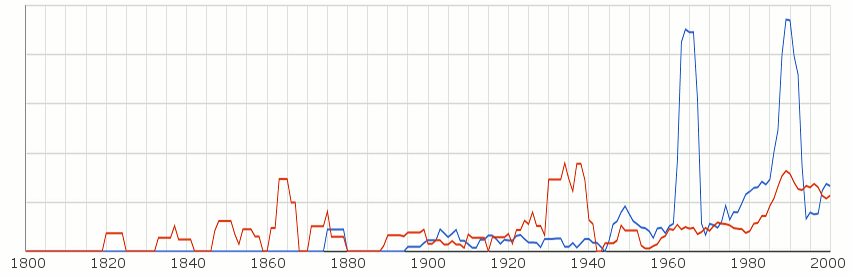
Следва споменаване на България и Македония (в червено) в английската литература. Вижда се как популяризирането на гръцката история в началото на 19-ти век води със себе си споменаване на регионът Македония. В този случай е трудно да се прецени контекста, в който се споменават имената. Вижда се обаче ясно пиковете на споменаване на България спрямо Македония. (оригинална графика)
 Натисни за по-голям размер
Натисни за по-голям размер
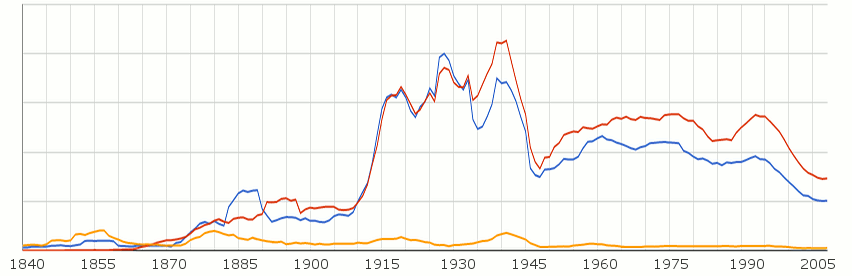
Тук виждаме споменаването на България и Румъния на немски език. Румъния е в червен цвят, а Walachei, както са наричали държавата в началото – жълт. Въпреки, че съседката ни се е освободила доста по-рано от нас, изглежда ние сме имали по-голяма видимост предвид размера на страната до войните. След това в немската литература се говори доста повече за Румъния, отколкото за България. (оригинална графика)
 Натисни за по-голям размер
Натисни за по-голям размер
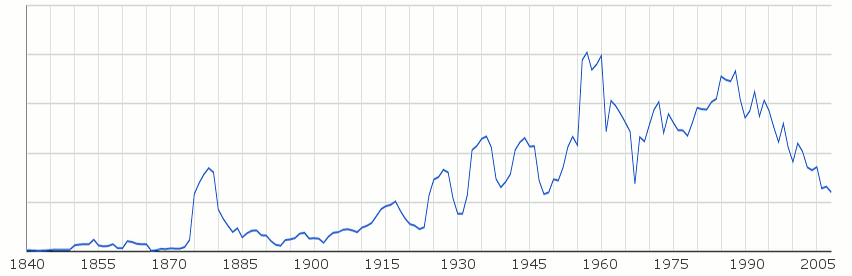
Следва споменаването на Батак в английските издания. Вижда се ясно пикът около Баташкото клане и няколко скока около войните в началото на 20 век. Забелязва се силно покачване в началото на комунизма и стабилно намаляване от началото на 90-те. (оригинална графика)
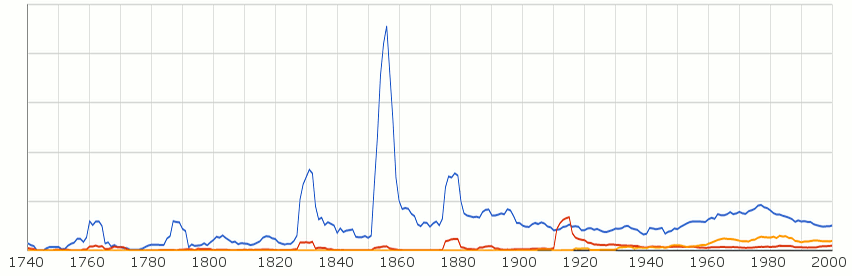 Натисни за по-голям размер
Натисни за по-голям размер
Следва сравнение между Варна (синьо), Бургас (червено) и Пловдив (жълто). Като важен морски град за Варна се е говорило много повече от останалите. За сравнение Пловдив изглежда е бил почти непознат. Възможно е изкривяване на данните, ако има други градове с такова има или има известно женско име Варна. (оригинална графика)

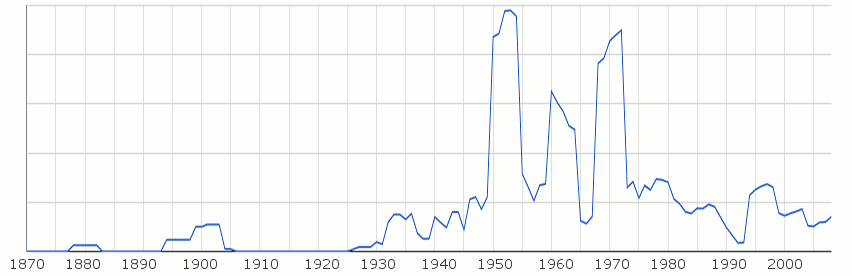 Натисни за по-голям размер
Натисни за по-голям размер
Последните две графики са споменаването на Левски на английски (горе) и на руски език (долу). Вижда се, че на руски се споменава няколко пъти малко след смърта му, докато на английски има споменаване дори докато е жив. Докато на руски има няколко сериозни скока през ’50 и ’70, на английки се говори от по-рано за него (вероятно в обзори и анализи) и става по-известен през ’70 и ’80. (оригинални графики на английски и руски)
Интересно ще бъде да се сравнят тези термини на френски, който до средата на 20-ти век е основният международен език. Още по-интересно ще е да се сканират всички книги, вестници и списания в Националната библиотека и да се изкара подобна графика.
В лекциите на TED, които споменах в началото, се говори и за индекс на цензура. Той се изчислява като се съберат отклоненията на различни автори на даден език. Тезата е, че когато има силен спад в отпечатаните творби на един автор или споменаване на определена фраза в даден период на даден език, то най-вероятно е имало цензура. Ако има силен скок – то най-вероятно има пропаганда. Така може да се изчисли средно за езика дали е имало много пропаганда или цензура. Там сравняват немския и английския. Интересно ще е да видим това за българския и руския.
Статистиката е хубаво нещо, но само когато извадката е правилно подбрана. В случая с думата „България“ търсенето трябва да е само по периодичен печат и то най-добре ежедневници. Само така можем да оценим скоростта на предаване на новините и отзвука за събитията. Разгледайте графиките на немски, френски, английски (британски и американски ) в областта 1870- 1878 и ще видите едно голямо нищо. Но то не отразява историческата истина. Инструментите трябва да се ползват по предназначение 😉
@ivo_isa – Доколкото знам са сканирали и много периодични издания. Търсейки отделни фрази открих доста вестници, някои от които български издания в Германия и щатите на английски и немски.
Първият пик на „Болгария“ през 20 век не съвпада с Първата световна, а по-скоро със събитията през 1923-25 – вероятно обилно отразени от съветската пропаганда.
Варна надали е сериозно повлияна от някакъв омоним – пиковете през 19 век ясно следват руско-турските войни (обсадата 1829, преминаване на западни войски през Кримската война и т.н.).
Ранните споменавания на Левски са очевидни false positives – отнасят се за 50-те години, когато още не се е казвал така. 🙂 (Всъщност са две пренесени с тире имена от рода на Ковалевски и някакъв руснак с тази фамилия.)
@Спас Колев – Явно изводите ми са грешни. Благодаря за поправките.
Ето нещо интересно от xkcd от същия dataset – честотата ма споменаване на различни дати в издания от 2000 насам:
http://xkcd.com/1140/